ITSM in der Praxis – IT-Service-Management (ITSM) klingt oft nach Prozessen, Formularen und Tools. In der Praxis geht es jedoch vor allem darum, verlässliche IT-Services zu liefern, die das Geschäft unterstützen und nicht blockieren. ITIL bietet dafür einen erprobten Rahmen, doch der eigentliche Unterschied entsteht erst, wenn Teams die Empfehlungen pragmatisch auf ihren Alltag übertragen.
In diesem Fachartikel erfahren Sie, wie ITSM mit ITIL-Bezug in der Praxis funktioniert, welche Prozesse sich als besonders wichtig erweisen und wie Sie den typischen Stolperfallen aus dem Weg gehen.
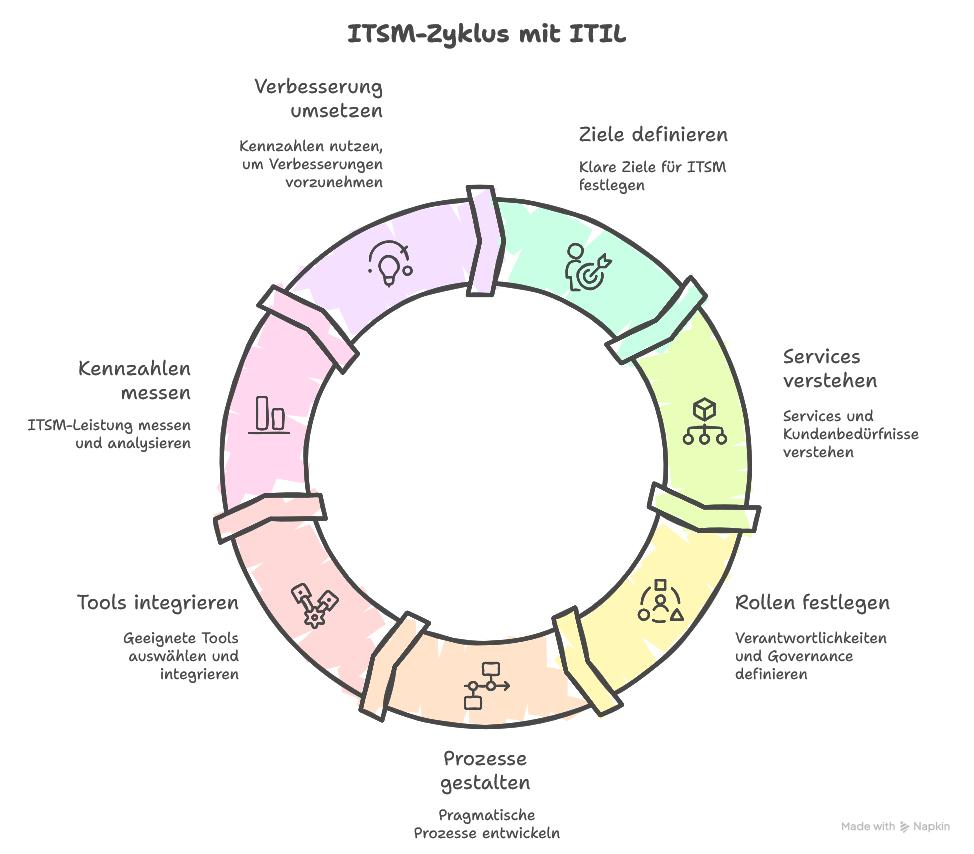
1. Was ist ITSM – und welche Rolle spielt ITIL?
ITSM beschreibt die Gesamtheit aller Maßnahmen, Prozesse und Strukturen, mit denen eine Organisation ihre IT-Services plant, bereitstellt, betreibt und verbessert. Der Fokus liegt nicht auf Technik, sondern auf Services, die messbaren Wert schaffen.
ITIL wiederum ist ein Framework mit Best Practices für genau dieses IT-Service-Management. Es liefert gemeinsame Begriffe, klar strukturierte Praktiken und typische Rollenbilder, damit Teams nicht jedes Rad neu erfinden müssen.
Wesentliche Grundideen von ITIL in der Praxis:
- Serviceorientierung: Nicht „Wir betreiben Server“, sondern „Wir liefern den Service E-Mail, Collaboration, ERP etc.“
- Wertorientierung: Aktivitäten sollen immer auf einen Beitrag zum Geschäftsziel einzahlen.
- End-to-End-Betrachtung: Vom Nutzer-Request über den Betrieb bis zur kontinuierlichen Verbesserung.
- Rollen & Verantwortlichkeiten: Klar definierte Zuständigkeiten, damit nichts „zwischen Stühlen“ landet.
- Kontinuierliche Verbesserung: Kein Design für die Ewigkeit, sondern fortlaufende Optimierung.
ITIL ist dabei ein Werkzeugkasten, kein Gesetzbuch. Erfolgreiche Unternehmen kombinieren dessen Empfehlungen mit ihrer eigenen Kultur und passen Umfang und Tiefe an ihre Größe sowie Reife an.
2. Zentrale ITIL-Praktiken im Alltag
In der Theorie listet ITIL zahlreiche Praktiken auf. In der Praxis kristallisieren sich jedoch einige Kernbereiche heraus, die fast jedes Unternehmen zuerst adressiert.
2.1 Incident Management: Störungen schnell und transparent lösen
Ziel: Den regulären Servicebetrieb nach einer Störung so schnell wie möglich wiederherstellen und Auswirkungen minimieren.
Typische Praxis-Elemente:
- Klarer Single Point of Contact (SPOC): Meist der Service Desk, an den sich Nutzer wenden.
- Strukturierte Ticket-Erfassung:
- Wer meldet das Problem?
- Welcher Service ist betroffen?
- Welche Auswirkungen bestehen (Person, Team, Standort, unternehmensweit)?
- Priorisierung nach Auswirkung und Dringlichkeit, nicht nach Lautstärke des Anrufers.
- Standardisierte Workflows für wiederkehrende Incidents (z. B. Passwort zurücksetzen).
- Kommunikation: Regelmäßige Statusupdates, damit Anwender wissen, woran sie sind.
Wichtig ist, dass das Incident Management nicht nur „Feuerwehr“ spielt, sondern Erkenntnisse auch an Problem- und Change-Management weitergibt.
2.2 Problem Management: Ursachen verstehen, nicht nur Symptome löschen
Ziel: Die Ursachen wiederkehrender oder schwerwiegender Incidents finden und nachhaltig beheben.
In der Praxis:
- Wiederkehrende Störungen werden regelmäßig analysiert.
- Techniker und Service-Desk-Mitarbeitende bewerten gemeinsam Muster und Häufungen.
- Es entstehen Problem-Tickets, in denen Teams Ursachenhypothesen festhalten.
- Methoden wie 5-Why-Analyse oder Ishikawa-Diagramm unterstützen die Ursachensuche.
- Die Umsetzung von Lösungen erfolgt häufig über Change- oder Release-Prozesse.
Viele Organisationen vernachlässigen dieses Thema, weil der Tagesbetrieb drückt. Genau deshalb lohnt sich ein festes Ritual, etwa ein monatliches Problem-Review mit klaren Entscheidungen.
2.3 Change Enablement (Change Management): Schneller ändern, ohne die Stabilität zu opfern
Ziel: Änderungen an Services und Infrastruktur so steuern, dass Risiken beherrschbar bleiben und Innovation trotzdem möglich ist.
In der Praxis bewährt sich eine klare Differenzierung:
- Standard Changes: Gut bekannte, risikoarme Änderungen mit vordefinierten Abläufen (z. B. reguläres Client-Update).
- Normal Changes: Änderungen mit moderatem Risiko, für die Teams Bewertung, Planung und Freigabe benötigen.
- Emergency Changes: Dringende Eingriffe, etwa Sicherheits-Patches bei kritischen Schwachstellen.
Für Normal Changes hat sich ein leichtgewichtiger Freigabeprozess bewährt, der Folgendes umfasst:
- Beschreibung des Ziels und der Änderung.
- Risiko- und Impact-Bewertung (fachlich und technisch).
- Plan für Rollout und ggf. Rollback.
- Terminplanung mit Rücksicht auf andere Aktivitäten.
- Dokumentation für spätere Nachvollziehbarkeit.
Entscheidend ist, dass der Prozess zur Organisation passt. Zu viel Bürokratie bremst Innovation, zu wenig Governance gefährdet die Stabilität.
2.4 Service Request Management: Standardanfragen effizient abwickeln
Ziel: Standard-Services (z. B. Software-Bereitstellung, Berechtigungen, Hardware-Bestellung) schnell, transparent und reproduzierbar zur Verfügung stellen.
Best Practices in der Praxis:
- Servicekatalog mit klar beschriebenen Standard-Requests.
- Self-Service-Portal, über das Mitarbeitende Anfragen stellen können.
- Vordefinierte Genehmigungswege, etwa für Kosten oder Sicherheitsrelevanz.
- Automatisierung, wo immer möglich (z. B. automatische Bereitstellung von Lizenzen).
Dadurch entlasten Unternehmen ihren Service Desk, und Nutzer erhalten häufiger standardisierte Qualität.
2.5 Configuration Management / CMDB: Wissen über die eigene Landschaft
Ziel: Ein belastbares Bild der IT-Landschaft und ihrer Abhängigkeiten schaffen, damit Entscheidungen fundiert ausfallen.
In der Praxis reicht selten eine „perfekte“ CMDB. Sinnvoller ist ein fokussierter Ansatz:
- Kritische Services identifizieren (z. B. ERP, E-Mail, zentrale Plattformen).
- Zentrale Configuration Items (CIs) dieser Services erfassen (Server, Datenbanken, Applikationen, Schnittstellen).
- Abhängigkeiten modellieren, damit Impact-Analysen bei Changes möglich sind.
- Datenqualität regelmäßig überprüfen, statt einmalig ein „Datenfriedhof-Projekt“ zu bauen.
3. ITSM mit ITIL-Bezug einführen: Ein pragmatischer Fahrplan
Viele Organisationen scheitern nicht an der Theorie, sondern an der Umsetzung. Ein schrittweiser, pragmatischer Ansatz erhöht die Erfolgschancen deutlich.
3.1 Ausgangslage und Ziele klären
Bevor jemand Prozesse „nach ITIL“ designt, sollte klar sein:
- Welche Pain Points dominieren aktuell (z. B. häufige Ausfälle, Intransparenz, lange Durchlaufzeiten)?
- Welche Geschäftsziele bestehen (Wachstum, Kostenkontrolle, Compliance, Kundenerlebnis)?
- Welche Reife hat die Organisation bereits (Prozesskultur, Toollandschaft, Rollenverständnis)?
Darauf aufbauend definieren Teams konkrete, messbare Ziele, etwa:
- Verkürzung der Incident-Lösungszeit um 20 %.
- Steigerung der Nutzerzufriedenheit im IT-Support.
- Reduktion ungeplanter Changes mit Ausfallfolge.
3.2 Services und Kunden verstehen
ITSM dreht sich um Services, nicht um Technik. Deshalb lohnt sich eine konsequente Service-Perspektive:
- Welche Services nimmt das Business tatsächlich wahr (z. B. „Digital Workplace“, „CRM“, „Produktions-IT“)?
- Wer sind die Kunden und Nutzer dieser Services?
- Welche Erwartungen an Verfügbarkeit, Reaktionszeit und Qualität bestehen?
Ein erster, grober Servicekatalog hilft, diese Sicht zu schärfen. Er muss nicht perfekt sein, doch er schafft eine gemeinsame Sprache zwischen IT und Fachbereichen.
3.3 Rollen, Verantwortlichkeiten und Governance festlegen
Ohne klar definierte Verantwortungen verwässern selbst gute Prozesse. Daher sollten Unternehmen folgende Rollen sauber klären:
- Service Owner: Verantwortlich für Qualität und Weiterentwicklung eines Services.
- Process Owner (z. B. Incident, Change): Verantwortlich für Design und Verbesserung des Prozesses.
- Process Manager / Lead: Verantwortlich für den operativen Ablauf im Alltag.
- Fachliche Key User in den Geschäftsbereichen als Bindeglied zur IT.
Hilfreich ist eine RACI-Matrix, in der Verantwortlichkeiten pro Aktivität dokumentiert werden. Dadurch erkennen Teams schnell, wer entscheidet und wer informiert werden muss.
3.4 Prozesse pragmatisch designen
Beim Design von ITIL-basierten Prozessen sollte weniger das Framework, sondern vielmehr die eigene Realität bestimmen:
- Start mit wenigen, geschäftskritischen Prozessen (typisch: Incident, Change, Request).
- End-to-End-Sicht entwickeln: vom Eingang der Anfrage bis zur Rückmeldung an den Nutzer.
- Nur die notwendigen Schritte dokumentieren, statt alle Eventualitäten zu normieren.
- Formulare und Masken schlank halten, damit Mitarbeitende sie wirklich nutzen.
Eine gute Praxis besteht darin, Prozesse zuerst skizzenhaft am Whiteboard zu entwerfen und sie anschließend in Tool-Workflows zu überführen. So bleibt der Fokus auf dem Inhalt, nicht auf Tool-Eigenheiten.
3.5 Tool-Auswahl und Integration
ITIL beschreibt das „Was“, nicht das „Womit“. Tools unterstützen die Umsetzung, ersetzen aber keine klare Prozessgestaltung.
Worauf es in der Praxis ankommt:
- Passende Komplexität: Ein globales Enterprise-Tool passt oft nicht zu einer kleinen IT-Abteilung und umgekehrt.
- Integration in vorhandene Systeme (z. B. Monitoring, Identity-Management, CMDB).
- Benutzerfreundliche Oberflächen, damit Tickets und Changes nicht im Schatten-IT-Kanal E-Mail enden.
- Reporting-Fähigkeiten, um Kennzahlen sinnvoll auszuwerten.
Teams sollten zuerst definieren, wie Prozesse aussehen sollen, und erst danach das Tool konfigurieren – nicht umgekehrt.
4. Erfolgsfaktoren und typische Stolperfallen
4.1 Wesentliche Erfolgsfaktoren
In Organisationen, in denen ITSM mit ITIL-Bezug gut funktioniert, lassen sich einige Muster beobachten:
- Top-Management-Support: ITSM gilt als strategisch wichtig, nicht nur als „Prozesshobby der IT“.
- Business-Einbindung: Fachbereiche wirken am Design der Services und SLAs aktiv mit.
- Schlanker Start, iterative Verbesserung: Lieber mit 70 % Reife starten und lernen, statt jahrelang „perfekte“ Prozesse zu planen.
- Transparente Kommunikation: Gründe für neue Abläufe werden erklärt, nicht nur verordnet.
- Fokus auf Menschen: Schulungen, Coaching und klare Erwartungen verhindern, dass Prozesse nur Papier bleiben.
4.2 Häufige Stolperfallen
Ebenso gibt es typische Fehler, die sich immer wieder zeigen:
- „ITIL als Religion“: Teams übernehmen Begriffe und Modelle unreflektiert, obwohl sie nicht zur eigenen Kultur passen.
- Überdokumentation: Handbücher umfassen hunderte Seiten, doch im Alltag liest sie niemand.
- Tool-getriebene Einführung: Erst wird ein Tool gekauft, danach versucht man, Prozesse hineinzupressen.
- Fehlende Change-Kommunikation: Mitarbeitende erfahren nur, dass es „ab morgen neue Tickets gibt“, und fühlen sich überfahren.
- Keine Zeit für Verbesserung: Alle sind im Tagesgeschäft gefangen, sodass Problem- und Continual-Improvement-Aktivitäten immer wieder verschoben werden.
Wer diese Muster früh erkennt und offen adressiert, erhöht die Erfolgschancen deutlich.
5. Kennzahlen im ITSM: Messen, was wirklich zählt
ITIL betont, dass Messgrößen immer einen Zweck haben sollen. Teams sollten deshalb bewusst auswählen, was sie verfolgen, und warum.
Typische Kennzahlen im Incident- und Service-Request-Umfeld:
- First Contact Resolution Rate (FCR): Anteil der Tickets, die beim ersten Kontakt gelöst werden.
- Average Resolution Time: Durchschnittliche Lösungszeit je Prioritätsstufe.
- Backlog-Größe: Anzahl offener Tickets je Kategorie.
- Nutzerzufriedenheit: Bewertung nach Ticket-Abschluss (z. B. via 3–5-Sterne-Skala).
Im Change-Umfeld sind häufig relevant:
- Change Success Rate: Anteil der Changes ohne unerwünschte Nebenwirkungen.
- Anteil ungeplanter Changes: Indikator für Reifegrad und Planungsqualität.
- Durchlaufzeit pro Change-Typ: Hilft, Flaschenhälse zu identifizieren.
Wichtig ist, dass Teams Kennzahlen interpretieren und in Maßnahmen übersetzen. Reine Berichte ohne Konsequenzen schaffen keine Verbesserung.
6. Praxisbeispiel: Vom reaktiven Helpdesk zum strukturierten Service Management
Stellen wir uns ein mittelständisches Unternehmen mit rund 800 Mitarbeitenden vor. Die IT betreibt mehrere Kernsysteme, doch der Alltag wirkt chaotisch. Störungen kommen per Telefon, E-Mail oder über Zurufe im Flur. Die Geschäftsführung ist unzufrieden, weil niemand sauber sagen kann, wie stabil die Services wirklich laufen.
Wie könnte eine pragmatische ITSM-Einführung mit ITIL-Bezug aussehen?
- Analyse-Workshop: IT-Leitung, Service Desk und Fachbereiche sammeln aktuelle Probleme. Schnell zeigt sich, dass Transparenz und Verlässlichkeit fehlen.
- Zielbild definieren: Die Organisation beschließt, zuerst Incident- und Request-Prozesse zu strukturieren, bevor komplexe Themen wie CMDB tief ausgebaut werden.
- Servicekatalog light: In zwei moderierten Sessions identifizieren Teams zehn Kernservices und beschreiben sie grob.
- Neues Ticket-System einführen:
- Alle Störungen und Anfragen laufen künftig über ein Portal oder den Service Desk.
- Standard-Requests (z. B. neue Software) erhalten vordefinierte Workflows.
- Schulung und Change-Kommunikation: Die IT erklärt offen, warum das neue Vorgehen eingeführt wird, und wie Anwender davon profitieren.
- Monatliches Service-Review: IT und Business betrachten gemeinsam Kennzahlen, etwa Ticketvolumen und Lösungszeiten, und beschließen konkrete Verbesserungsmaßnahmen.
Innerhalb weniger Monate steigt die Transparenz deutlich, und die IT kann erstmals belastbare Aussagen über Servicequalität liefern. Auf dieser Basis lassen sich später Problem Management, Change Enablement und ausgewählte CMDB-Bereiche weiter ausbauen.
7. Fazit ITSM in der Praxis: ITIL als Leitplanke, nicht als Zwangsjacke
ITSM in der Praxis bedeutet, Services verlässlich, nachvollziehbar und geschäftsorientiert zu erbringen. ITIL liefert dafür eine gemeinsame Sprache und einen gut gefüllten Werkzeugkasten. Dennoch entscheidet die Umsetzung über den Erfolg.
Wenn Unternehmen ihre Ausgangslage ehrlich analysieren, die wirklich wichtigen Services und Prozesse fokussieren und Mitarbeitende aktiv einbinden, entsteht Schritt für Schritt ein reifes Service Management. ITIL dient dabei als Leitplanke, während Organisationen ihren eigenen, passgenauen Weg gestalten.